SCALE Benchmark case study: GROMACS

Chris Kitching
Mon May 19 2025
With the release of version 1.3.1, SCALE has reached a major compatibility milestone: the ability to run the CUDA version of GROMACS on AMD GPUs.
This is an exciting moment for us, since GROMACS is a large and complex CUDA project. Getting to this point involved overcoming a number of stubborn issues in our compiler, and is a positive sign for how mature the SCALE platform is becoming.
Since version 2025.0, GROMACS has begun to offer AMD GPU support via a HIP port. Our work is unrelated to that effort: SCALE compiles CUDA source code directly to AMD machine code, no porting required. This allows us to run even older versions of GROMACS that predate the HIP port.
We've tested correctness on GROMACS 2024.4 and 2025.1, and are excited to present the results of our performance benchmarking on 2025.1.
Performance Comparison to HIP port
Since GROMACS has an ongoing HIP port, it offers a valuable opportunity to perform a direct performance comparison. Projects that have no existing AMD GPU support are more challenging to evaluate, since it will necessarily involve comparison of runs on NVIDIA hardware against those on AMD hardware. While valuable, such runs are not ideal as a direct measurement of the performance impact of SCALE: we want to measure how close we’re getting to our goal of matching or exceeding the performance of a HIP port.
The chart below shows the relative performance of HIP (ROCM 6.3.1) vs. SCALE 1.3.1 on the Max Planck Institute GROMACS benchmarks, running on a single MI210 GPU. Negative performance improvement represents cases where SCALE was slower than HIP, while positive values represent performance improvements.
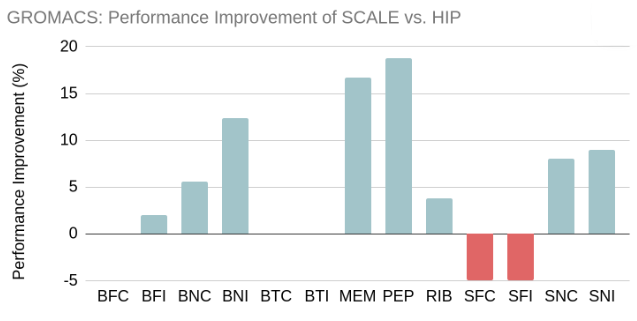
As shown in the graph, our performance is broadly comparable to HIP, and sometimes significantly faster. An important caveat here is that the HIP port is incomplete, so some of these wins are simply a result of SCALE using the GPU for more of the work. To reduce this effect, we disabled the CUDA acceleration of PME tasks for the SCALE runs, since those currently lack a HIP port. As a result, real-world users of GROMACS with SCALE should see somewhat better performance than depicted here.
To get a more fine-grained understanding of the differences seen here, we turn to GROMACS’ internal performance counters. These measure the time spent in each part of the application, allowing us to directly compare the performance of individual kernels (or groups thereof) compiled with SCALE vs. their HIP replacements. Since there is not a 1-1 mapping between CUDA kernels and HIP kernels in the two implementations, this approach is more meaningful than simply timing individual kernels.
The output from these performance counters is shown in the table below:
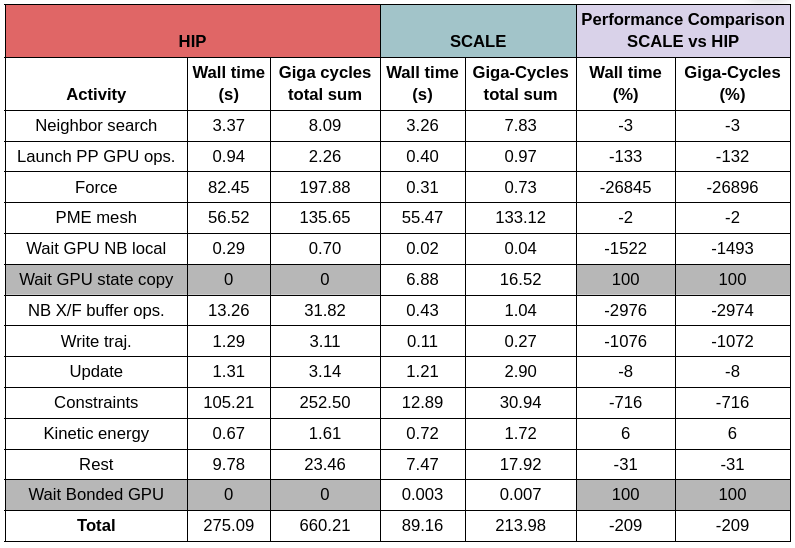
The cases where SCALE is dramatically ahead (e.g. “Force”) are examples of cases where the HIP code simply hasn’t been written yet, so it’s comparing CUDA-with-SCALE to CPU, which isn’t particularly interesting. What’s encouraging is that in the other cases, SCALE is still coming out slightly ahead or on-par with HIP, suggesting that when GPU code does exist in both versions, the results are broadly similar on each. These improvements represent cases where our compiler or runtime library has outperformed the HIP version.
These measurements demonstrate the idea that CUDA code can be compiled for AMD hardware without a “performance tax": it’s just a matter of doing the necessary compiler/platform work to make it happen. As we iterate on performance in the coming months, we anticipate more exciting results to share with the community. Since SCALE is a platform, not a per-project porting effort, performance benefits will benefit a wide range of CUDA applications, not just the ones for which we publish benchmarks.
Try it yourself
If you want to reproduce these results yourself, you can find the scripts we use to build, test, and benchmark GROMACS here: https://github.com/spectral-compute/scale-validation/tree/master/gromacs
That repository contains similar scripts for other projects we use for validation. Check out the README for more information, and consider contributing scripts for projects you care about. Adding real user code to SCALE’s test suite helps us improve the product further.
The free edition of SCALE offers support for RDNA GPUs. If you want to obtain evaluation/academic access to SCALE Enterprise - which offers CDNA support - please get in touch
Bugs? Send a report
Looking forward
Although the results presented above are encouraging, we recognise that there's still significant work to do. So far, our focus has been on expanding SCALE's API completeness/compatibility to the point where enough real-world projects work out of the box. For our next major release, we are switching focus more towards improving performance of the platform. We believe that SCALE is significantly more compelling when it has competitive (or superior) performance compared to HIP: if the CUDA version of your project is just as fast, then using SCALE offers a promising alternative to a costly HIP port.