It's Been a Minute

Michael Søndergaard
Mon Nov 10 2025
A Big Update from Spectral Compute, the team behind SCALE.
Hey World
Yeah, we know, it’s been a while. We’ve been heads-down, buried in code, and frankly, just incredibly busy making CUDA work everywhere.
So, grab a coffee. We’ve got a lot to catch you up on.
We’re Spectral, the company behind SCALE, which we’ve been quietly developing for the past six years. Then, last year, we nervously pushed the "release" button on the SCALE beta. It blew up. Seeing our work hit the front page of Hacker News and get covered by Phoronix, Tomshardware and so many other news outlets was a wild ride. That response confirmed what we always believed: the world needs SCALE. A way to use CUDA code on any chip. It's why this year, we're all in. We’re now a venture-backed startup, having raised $6 million from our incredible new partners at Costanoa Ventures, Crucible Capital, and 12 amazing angel investors - all to bring SCALE to the entire chip developer ecosystem.
We’re All-In on SCALE
We genuinely believe SCALE is as revolutionary for the GPU space as C compilers were for CPUs.
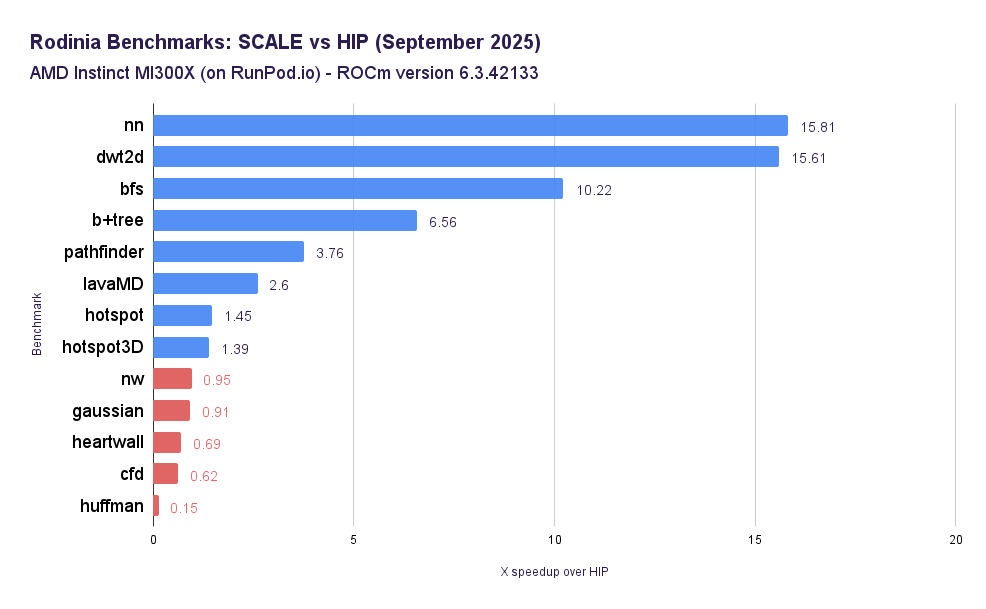
While it may be harder than creating a new language or trying to JIT what comes out of NVIDIA's compiler, we believe true ahead-of-time compilation of CUDA code is the right solution to this problem, just like it was 20 years ago for bringing C to more CPU architectures. We’re building the entire toolkit to achieve that: we’re implementing CUDA-X library replacements, CUDA Runtime and Driver APIs, etc. And we actually found our toolkit outperformed alternatives, in many cases (average speedup for this test suite: 4.67x)
GPU Portability or, a Maze of Dead Ends
The CUDA software ecosystem is massive. Because of that, nobody really wants to reinvent the wheel. To break free from the hardware vendor lock-in, the approach was to port, use translation layers or new languages, all of which have distinct drawbacks.
| Tool | ZLUDA | HIP | OpenCL | Mojo |
|---|---|---|---|---|
| Benefits | "CUDA Compatible" | Open source | Open standard | Supports NVIDIA and AMD |
| Can support (most) programs without recompilation | "Looks like CUDA" | Supported by most vendors | Cool new language | |
| Drawbacks | Requires use of NVIDIA toolkits | Requires significant effort in porting and subsequent maintenance | Restricted language features | Significant porting and integration efforts from CUDA required |
| Being rewritten because of legal clawback from AMD | Mainly targets AMD (usually fails on NVIDIA due to target-unlisted backend) | Significantly smaller ecosystem | In making "Python" performant, it ends up looking like CUDA C++ without getting the ecosystem benefits | |
| No AMD data center grade GPU support | Significantly smaller ecosystem | |||
| Needs DLL injection, flagged as malware on Windows | Significant stability and support issues 1 | |||
| Unfinished code has problem* (loss of info needed for re-optimization for AMD architectures) | ||||
| Cannot match performance of native CUDA | ||||
| Uses HIP runtime |
That’s why we’re placing all our chips (eheheh) on SCALE. It’s our bet - and we think it’s the most clear-sighted approach for the entire ecosystem: abstracting the complexities at the compiler layer and finally run these workloads on any architecture.
Our Secret Sauce: The Team
We’ve had more than a few people tell us, "what you're doing is impossible.". And, you know what? It is incredibly difficult. That’s probably why nobody else has been crazy enough to take on this mission. But our R&D team has a combined experience that’s closing in on two centuries. If anyone can deliver on this promise, it’s this crew.
We are an amazing, growing team of around 20 people, including some brilliant new folks in our sales and marketing departments (welcome!). But the real MVPs, the absolute strength of this company, are our engineers.
Thanks to them, we’re steadily shipping new versions of SCALE that are already running in production and being tested in PoCs with new prospects as we speak.
Announcing: SCALE v1.4.2 now with CUTLASS Support
Speaking of shipping... we’re stoked to announce the release of SCALE v1.4.2, which (drumroll, please) includes support for CUTLASS!
This is a massive milestone for us. We had previously focused on the broader HPC area of compatibility. Now, getting CUTLASS to work at all has been the first giant compatibility hurdle in the AI/ML workload part of the equation, and we've officially cleared it.
Now, to manage expectations (and be totally transparent): it's not winning any speed records just yet. This first release is all about proving compatibility. Right now, our compiler R&D team are deep in the trenches, doing the hard work to optimize and deliver the usable performance you'd expect. You can grab SCALE v1.4.2 from here and use it for non-commercial purposes - tell us what you break.
This is the necessary groundwork to bring SCALE to the wide world of AI/ML workloads, and it gets us one giant leap closer to...
What's Next on the Roadmap
PyTorch support! This is the big beast we’re currently focused on taming. We have a long list of prospects who’ve told us, "Call us back as soon as you have PyTorch running." We hear you, and we’re on it.
Then we need to cover vLLM, SGLang and CuTile, presented by NVIDIA at Pytorch Conference 2025 last month, which we attended. We are genuinely hyped about this. Tools like Triton are cool, no doubt. But CuTile is hitting on something we've been waiting for: bringing that powerful, tiled approach inside the CUDA ecosystem, where it belongs. NVIDIA is set to either open-source the CuTile->TileIR compiler and push it to upstream LLVM, or at least provide open specs for it. Either way, they're (of course) keeping the final machine-code compiler proprietary. That, right there, is our cue. We’ll be the ones building the backend that connects that new paradigm straight to AMD hardware.
Considering all of the above, along with substantial performance enhancements and a few cool secret projects, 2026 is poised to be the year SCALE unlocks the majority of the workloads you’d expect it to happily gulp down and compile. Get ready.
Come Say Hi!
We’re building all this cool stuff, and now want to make sure people actually know about it We’ve revamped our websites (go check out spectralcompute.com and scale-lang.com) and given our brand a fresh coat of paint.
We’re also getting out in the press more. We just had an awesome interview with Business Insider. You can check it out here.
We’ll also be at SC25, the Conference for High Performance Computing in St. Louis. We are so excited to be there to talk about... well, all of this. Come say hi at Booth #6552.
If you want to get serious and talk shop, you can schedule a 1-on-1 time slot with us at this link. Otherwise, just swing by the booth! We’d love to have a chat, and you’re more than welcome to "steal" as much of our cool new handouts as your bag can hold. We’re also planning some chill, post-event meet-ups. If you want to grab a beer with the team, drop us a line on our Discord or reply to the Reddit post on the topic.
That’s the update. It feels good to be back. We’ll try not to be strangers.
Cheers, yours
- Michael.