CUDA, the De Facto Standard of HPC?

Giulio Malitesta
Tue Mar 10 2026
For nearly two decades, NVIDIA’s proprietary programming model, CUDA, has been the "gold standard" for unlocking the capabilities of the GPU. In June 2024, Jensen Huang announced that the ecosystem has reached 5 million developers1, growing ~150% from a 2M-developer userbase in 20202. This figure is a conservative floor; since registration isn't required on the NVIDIA download page and many install CUDA via package managers or Docker, the actual user base is likely much larger.
With SCALE, we treat CUDA as the de facto standard for HPC workloads, allowing developers to compile their unmodified CUDA code for non-NVIDIA architectures. But this assumption is increasingly being challenged. New languages and paradigms - from HIP and SYCL to Pythonic HPC approaches - promise a future where developers are no longer locked into NVIDIA's hardware.
Is this the beginning of a multi-vendor revolution, or is CUDA's lead unbeatable? To find out, we did some research to probe the current developer landscape.
The Contenders
| CUDA (2006), developed by NVIDIA as the GPGPU first-mover. | OpenCL (2009), proposed by Apple and maintained by the Khronos Group. | SYCL (2014), a Khronos Group standard for modern, "single-source" C++. | HIP / ROCm (2016), launched by AMD to challenge NVIDIA’s dominance. |
|---|---|---|---|
| Approachable "C++-like" syntax and a vast library ecosystem (cuBLAS, cuFFT). | Open, royalty-free standard for cross-vendor portability (NVIDIA, AMD, Intel). | Targets heterogeneous computing with host and device code in a single file. | Syntactic "dizygotic twin" to CUDA, allowing a shared codebase for NVIDIA and AMD. |
| Low barrier to entry: accelerate standard C89 code via libraries before moving to custom kernels. | Requires significant boilerplate code due to its low-level nature. | Unique design enables potential for novel compiler optimizations across the host/device boundary. | Includes HIPIFY to automate the porting of CUDA code directly to HIP, with limitations. |
| Proprietary and exclusive to NVIDIA hardware. | Often less attractive to developers compared to higher-level abstractions. | Core of Intel’s oneAPI initiative for multi-vendor architecture development. | Positioned as a bridge for existing CUDA investments. |
Methodology
Raw Code Footprint via GitHub Search (Web UI)
First, we analyzed the volume of active codebases on GitHub using targeted search queries.
- CUDA, OpenCL, and HIP: We leveraged GitHub's native language classification and searched for
language:CUDA,language:OpenCLandlanguage:HIP. It is important to acknowledge the concern that GitHub may incorrectly classify HIP code as CUDA; we address this overlap in later steps. - SYCL: Because SYCL often resides in standard C++ files, we quantified its presence by summing results for core header inclusions, specifically
#include <CL/sycl.hpp>and#include <sycl/sycl.hpp>. This approach may positively skew results as both core headers could appear in the same codebase.
Intentional Tagging via GitHub Topics
To measure intentional developer alignment, we analyzed GitHub Topics. We counted repositories where developers explicitly tagged their project with a specific framework.
- The specific queries used were:
topic:cuda,topic:opencl,topic:sycl, andtopic:hip.
Idiom Analysis via GitHub REST APIs
Next, we searched for toolkit-specific idioms in active codebases. We used extract_cuda_without_hip.py and measure_alt_hpc_adoption.py to query for the syntax used to define or launch kernels.
- Code Idioms:
cudaMalloc(CUDA),clCreateKernel(OpenCL),sycl::queue(SYCL), andhipLaunchKernelGGL(HIP).
Because HIP codebases often contain standard CUDA API calls like cudaMalloc for cross-platform support, relying solely on keyword searches overcounts true CUDA lock-in in this specific case. To refine our research, extract_cuda_without_hip.py subtracts any repository containing AMD's hip_runtime.h from our baseline CUDA results. During data collection, occasional warnings indicating "Bin [X] returned 1000+ files" occur when a specific file-size interval hits GitHub’s hard limit of 1,000 results per query. However, because our methodology tracks unique repositories across over 150 different size bins, a project is only missed if every single one of its matching files falls into truncated bins. Consequently, these warnings indicate that the final repository count is a lower bound. The logs and output of each script can be found here.
Academic Mindshare via Semantic Scholar API
We developed a Python tool (academic_research.py) to interface with the Semantic Scholar Graph API. We queried paper metadata for the years 2020 through 2025 to measure research momentum, signaled by any of the following strings:
- For CUDA:
"CUDA" | "NVIDIA GPU" | "cuBLAS" - For HIP:
"HIP" | "ROCm" | "AMD GPU" | "MI250" - For OpenCL:
"OpenCL" | "SPIR-V" - For SYCL:
"SYCL" | "OneAPI" | "DPC++" | "Intel GPU"
This research is limited by the fact that generic terms like "AMD GPU" might capture papers that aren't specifically about the HIP programming language.
Research scope and limitations
This research is limited to publicly available codebases on GitHub and published academic papers. We cannot investigate proprietary, "closed-source" enterprise codebases. Empirical business experience suggests that the dominance of CUDA in the private sector is even more pronounced; alternatives are often relegated to side-projects aimed at proof-of-concept (PoC) portability.
Quantifying the Dominance
GitHub: The "Developer Desert" for Alternatives
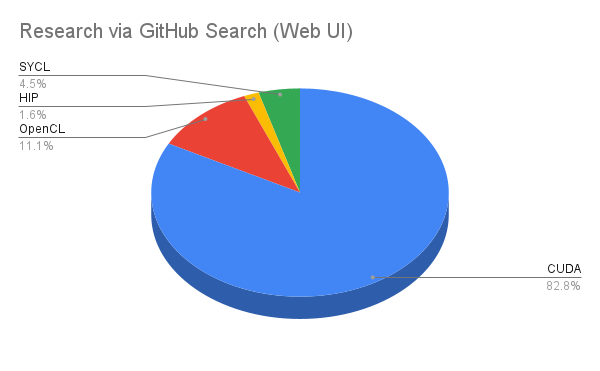
When we analyzed the raw code footprint on GitHub, the disparity was staggering. Below is the breakdown of the raw ecosystem metrics collected via the GitHub Search UI.
| Language/Framework | Files | File Share (%) | Repos | User Share (%) | Method |
|---|---|---|---|---|---|
| CUDA | 692,000 | 82.79% | 35,400 | 99.76% | Research query: language:CUDA |
| OpenCL | 92,700 | 11.09% | 03 | 0.00% | Research query: language:OpenCL |
| SYCL | 37,600 | 4.50% | 04 | 0.00% | Research query: sum of results for #include <CL/sycl.hpp> and #include <sycl/sycl.hpp> queries. |
| HIP | 13,600 | 1.63% | 85 | 0.24% | Research query: language:hip |
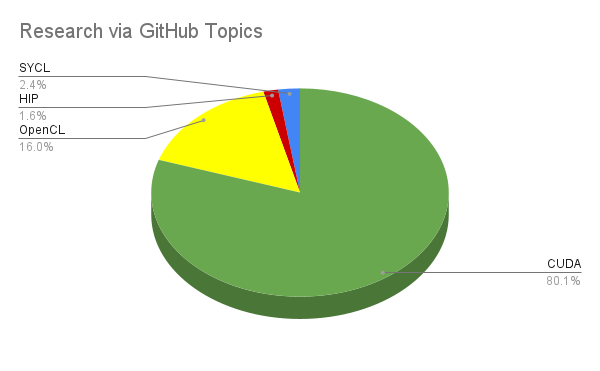
We collected similar results by interrogating GitHub Topics. This metric represents repositories where developers explicitly tagged their project with a specific framework, showing intentional alignment. Interestingly, HIP retains the same percentage here as in the previous raw file search. This consistency suggests that GitHub’s potential misclassification of HIP code as CUDA may be less significant than generally assumed.
| Topic Tag | Repositories | Share (%) | Method |
|---|---|---|---|
| CUDA | 6,657 | 80% | "CUDA topic": topic:cuda |
| OpenCL | 1,326 | 16% | "OpenCL topic": topic:opencl |
| SYCL | 196 | 2.4% | "SYCL topic": topic:sycl |
| HIP | 134 | 1.6% | "HIP topic": topic:hip |
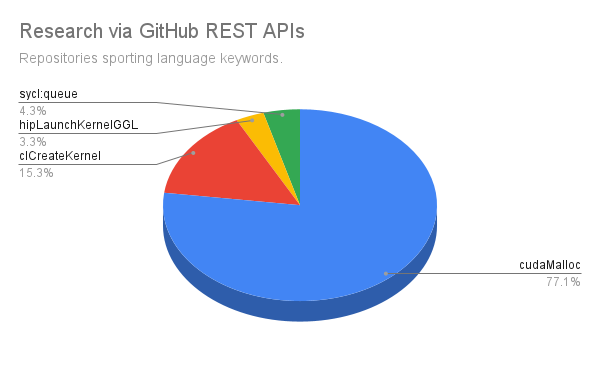
Similar findings were observed by searching for indications of active codebases that sport specific code idioms.
| Signature | Language | Repos | Share (%) |
|---|---|---|---|
cudaMalloc | CUDA | 59,950 | 77.1% |
clCreateKernel | OpenCL | 11,887 | 15.3% |
sycl::queue | SYCL | 3,355 | 4.3% |
hipLaunchKernelGGL | HIP | 2,599 | 3.3% |
Academic Research
While researchers are increasingly interested in cross-vendor portability, results show the baseline volume of academic publications remains heavily skewed toward NVIDIA's ecosystem. Our analysis of paper count from 2020 to 2025 shows that CUDA maintains an overwhelming 82.83% incidence in academic research related to GPU programming and accelerated libraries. Academic interest in CUDA peaked at 193 papers in 2025 alone, exceeding the sum of all alternatives considered.
| Metric | CUDA | HIP | OpenCL | SYCL |
|---|---|---|---|---|
| Total | 912 | 12 | 111 | 66 |
| % | 82.83% | 1.09% | 10.08% | 5.99% |
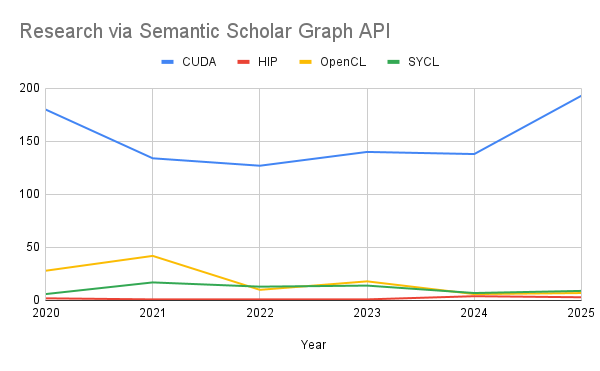
While we continue to see case studies and benchmarks testing SYCL and HIP, the data suggests these represent a residual interest or a niche academic focus on portability rather than a ‘shifting tide’. The amount of academic interest for all alternative programming languages appears stable or even decreasing, while CUDA's dominance in research output continues to accelerate. However, because studies on the limits of performance portability offer valuable insights, we have compiled a few notable examples in the Appendix at the end of this post.
The Economic Moat
Beyond the technical architecture, there is a powerful economic engine sustaining CUDA’s dominance. Our research suggests that the "moat" is built on three pillars of enterprise risk management:
- The Talent Tax: The most significant factor is the global workforce. With more than 5 million developers already proficient in CUDA, the industry cannot afford the "talent tax" of retraining this massive population on new languages. For most enterprises, accepting CUDA as the standard is a more sensible economic decision than funding a multi-year retraining program. Expertise is the hardest layer of the stack to swap.
- Production Reliability and Sunk Cost: Transitioning from CUDA to a different hardware abstraction effectively asks enterprises to throw away their existing investments in validation and QA. When a codebase is "production-proven" on CUDA, the perceived risk of moving to an unproven ecosystem - where subtle compiler bugs or performance regressions could derail a mission-critical project - is often too high to justify.
- Saturation and the Failure of Alternatives: With NVIDIA holding ~90%5 of the HPC infrastructure market, CUDA has effectively become the "source code" for expressing accelerated computing. Many attempts to break this monopoly have inadvertently reinforced it; by building new stacks or languages, challengers often just "trade one lock-in for another" rather than solving the core problem of portability. This lack of a truly neutral, performant alternative has consolidated CUDA's position as the only safe bet for large-scale infrastructure.
Conclusion: Is CUDA the De Facto Standard?
Yes.
Based on our findings, CUDA remains the undisputed de facto standard for HPC and AI. While SYCL is emerging as a powerful, modern C++ alternative and HIP provides a necessary bridge for AMD hardware, their raw code prevalence is not near that of CUDA. The industry is talking about portability in academic papers, but it is still writing CUDA in the repositories.
To dethrone CUDA, challengers don't just need a better language - they need to replicate twenty years of optimized libraries and developer trust. This is why the industry needs a solution such as SCALE that doesn't ask users to throw away their production-tested investments, but rather unlocks bringing that source code to new hardware.
Appendix
Case Studies on Performance Portability
- Bioinformatics (SW# Case Study): Researchers evaluating the Smith-Waterman protein database search found that SYCL achieves performance comparable to CUDA on NVIDIA hardware while providing "remarkable code portability" to AMD and Intel architectures.
- The Gaia Mission (AVU-GSR): A performance assessment of the ESA Gaia mission pipeline demonstrated that HIP reached a 0.94 performance portability score, while SYCL reached 0.93, proving these alternatives can achieve over 90% of native CUDA efficiency in complex astrophysical solvers.
- Molecular Dynamics (GROMACS): Developers adapted GROMACS to use SYCL to target AMD-based supercomputers like Frontier and LUMI, confirming that portability is achievable without major compromises to performance at exascale.
- Virtual Screening (LiGen on LUMI-G): A study on the LUMI-G supercomputer showed that SYCL implementations could effectively handle molecular docking on AMD GPUs, even exceeding native throughput in some optimized out-of-kernel configurations.
Footnotes
Footnotes
-
(Reuters) TAIPEI-NVIDIA CEO HUANG: WE NOW HAVE 5 MILLION CUDA DEVELOPERS AROUND THE WORLD ↩
-
https://blogs.nvidia.com/blog/2-million-registered-developers-breakthroughs ↩
-
Note: Repository and User detection for OpenCL did not return any result. ↩
-
Note: Repository and User detection for SYCL did not return any result. ↩
-
Approximative average considering the following sources: carboncredits.com, January 6, 2026 (92%), ainvest.com, 14 February, 2026 (92%), finance.yahoo.com, June 6, 2025 (92% including consumer market share), finance.yahoo.com, January 25, 2026 (85% including consumer market share). ↩