GROMACS on SCALE: A Quick Update

Tue Dec 16 2025
After our first GROMACS post back in May, we kept digging into the parts of the CUDA backend that GROMACS relies on, especially after getting a very helpful email from the GROMACS Team. Their feedback pointed out a few places where our original evaluation or implementation wasn’t quite right. So this post is a short update on what changed since then and where things stand now.
CUDA Graphs: Finally Working
One of the biggest gaps in our previous setup was CUDA Graph support. GROMACS uses CUDA Graphs a lot more heavily than we initially realized. Several tests were failing for exactly that reason. Over the past few weeks we implemented the missing pieces:
- Recording events (including the oddities around
cudaEventRecordWithFlags,cudaStreamBegin/EndCapturewith the global semantics) - Making stream capture and graph execution behave the way CUDA does
- Proper handling of graph nodes for kernel launches and copies
- The IPC event edge cases that show up only in real workloads
After wiring all that up, the full GROMACS CUDA test suite now passes on SCALE. This was a good milestone for us because it shows that the CUDA backend inside GROMACS is interacting with SCALE in the way it expects.
Feature Coverage: SCALE vs HIP, SYCL, and CUDA
Another thing that came up was the comparison with HIP. The HIP backend in the official GROMACS 2025 release doesn’t offload everything to the GPU yet. PME tasks run on the CPU, which affects both performance and comparability. SCALE, on the other hand, supports the same tasks as CUDA tasks because they’re implemented in CUDA inside GROMACS already. Consequently, SCALE can offer a drop in replacement for the CUDA version of GROMACS removing the need to maintain multiple code bases. To verify that SCALE supports the same features as CUDA, HIP, and SYCL we execute the unit tests provided from GROMACS and notice that we execute the same number of tests as all these codebases.
Updated Performance Results
We also redid our evaluation using the latest GROMACS release (2025.4) and a more consistent setup based on GROMACS team suggestions:
- HIP is run with
-pme cpu -bonded cpu -update cpu - We use wall-clock time normalized to SCALE as the comparison metric
-resetstephelped to remove noise in short runs- We used
smito inspect GPU utilization instead of relying on indirect counters
A few takeaways:
- SYCL is currently the fastest backend on AMD GPUs. That shouldn’t surprise anyone — SYCL support in GROMACS has been tuned for years and is used heavily on systems like LUMI.
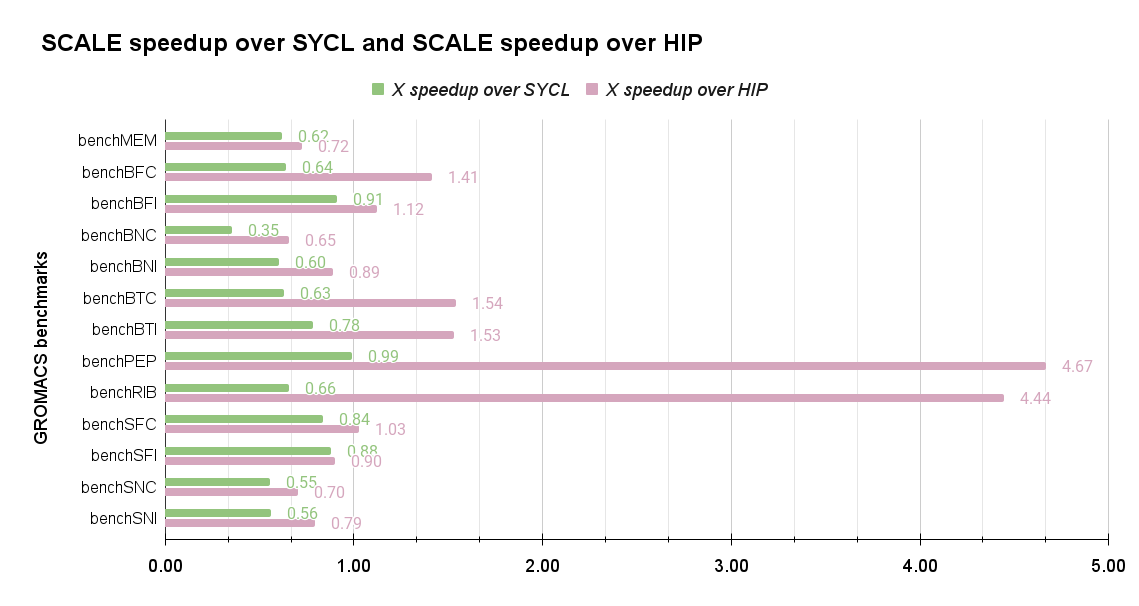
- SCALE is one average 1.5× slower than SYCL but about 1.6× faster than HIP.
- GPU utilization of SCALE and SYCL is much higher than HIP - which is because parts of the workload of the HIP case are executing on the CPU.
This aligns well with our goals: for now, SCALE’s priority is compatibility, not beating hand-tuned backends like SYCL. Performance work will come next. The figure below shows the speed-up or slow-down (when values are below one) for SCALE-HIP, and SCALE-SYCL. For our evaluation we use an AMD Radeon PRO MI210 (gfx90a), the GROMACS version is 2025.4, and the ROCm version is 6.3.1. We also tried ROCm 7.1.0 but AdaptiveCpp does not support it and we ended up with compile errors in GROMACS.
What’s Next
This round of fixes — especially CUDA Graphs — puts us in a much better position to optimize performance without worrying that we’re missing functional pieces. Our next steps will focus more on kernel code optimizations and other parts of the runtime where we know there’s room to improve. We'll also be testing GROMACS compiled with SCALE to run on NVIDIA GPUs (sic).
More updates soon.